前言
这主要是 @AskaNeverEnd 引发的血案。AskaNeverEnd 跑去澳洲不学好,用起了 Jmeter。昨天,他突然问了一个问题,如何用 Jmeter 登陆 Https 的网站。于是我就跑去 Jmeter 官网翻有关 SSL 的信息,发现各种纠结。看文档实在是累啊,于是正好手头项目是用 Https, 不妨一试。结果 Https 没怎么试验,倒是体验了一把 Xpath Extractor。
需求
大家都知道,传统的表单登陆有几个特点:
- 有一个特定的 action
- 使用 Post 协议
- post 参数一般为用户名和密码
- 有很多的 hidden input 随机值
比如百度的登陆,就有相当多的 hidden input。这些 hidden input 的 value 在每次请求时,都会随机生成不同的值。所以你不得不把它提取出来,参数化。于是我们就用到了 XPATH Extractor。
实践
假设我们有这样一个登陆的form:
<form action="/login" method="post">
<input id="username" name="username" type="text" value="">
<input id="password" name="password" type="password" value="">
<input type="hidden" name="lt" value="20120001">
<input type="hidden" name="_eventId" value="submit">
<input class="btn-submit" name="submit" value="Log In" type="submit">
</form>
可以看到有两个 hidden input, 其中 lt 值是每次刷新页面时候,随机生成的值,另外一个是固定。那我们的策略是:
- 第一次请求这个页面时候,获取随机生成的 lt 值。
- 用这个获得的 lt 值,和用户名,密码一起做为 post 的参数,传递到后台去。
所以在jmeter里面,先创建一个 HTTP 请求,这个请求的作用就是访问网站登录页面,并在这个请求填加后置处理器: XPATH Extractor,来提取请求返回的 html response 里面的 lt 的值。

然后在 XPATH Extractor 里,将要提取 lt 的 XPATH query 填写正确, 如下

在第一个 http 的请求中,我们取得了 lt 的值。接着我们创建第二个 http request, 这次要完成的就是将这些参数 post 到 form 制定的 action 中去。

需要注意的是,这次的方法变成了 Post, 还有参数都要填写到参数列表中,注意那个 lt 值, jmeter 使用 ${} 获取参数的值。
好,大功告成,试试看吧。
XPATH Extractor 详说
盗用下Apache上的图片: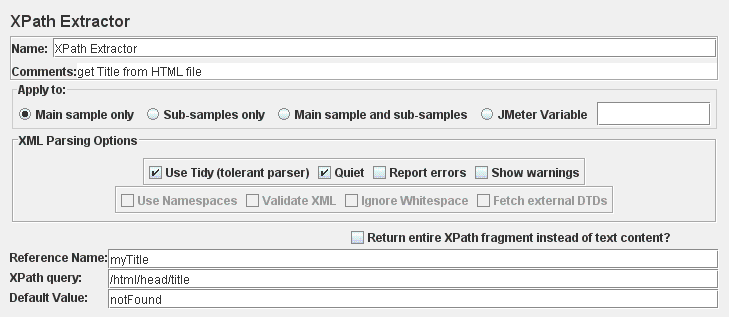
我们来一一解说下,这些图片上的属性,英语好的人可以直接移步 Apache Jmeter Xpath Extractor。
Name: XPATH Extractor, 就是一个该节点的描述信息,你可以任意更改,会立刻反应在你的节点树上。
Comments: 同样也是描述信息。
Apply to:一般只针对于那些有子 sample 的 sample, apply to 有4种:
- Main sample only: 只对主 sample 起作用。
- Sub-samples only: 只对子 sample 起作用。
- Main sample and sub-samles: 两种都起作用。
- JMeter Varibale: 这个变量是用于 JMeter的assertion, assertion 会对这个变量的内容起作用。
XPATH的会对每一个被 Apply to 的 Sample 依次起作用, 并所有的匹配结果都会返回。
XPATH Parsing Options
Use Tidy(tolerant parser): 如果选择 Use Tidy, 就是解析response的时候将 HTML 转成 XHTML。
- 对于所有的 HTML response, 我们应该选择 Use Tidy, 这样的 response 会被转为有效的 XHTML。
- 对于所有的 XHTML 和 XML, 就不需要再选择使用 Use Tidy 了。
Quiet: tidy 的 quiet flag 设置, 选中了会抑制一些不必要的输出。
Report error: 如果 Tidy 发生错误, 那么触发相应的 Assertion。
Show warnings: 显示 Tidy Warning 信息的开关。
Use Namespaces, Validate XML, Ignore Whitespace, Fetch External DTDs 这四个只有在 Use Tidy 没有选中才会被激活。
Use Namespaces: 如果选中此选项,那么 XML 解析器会使用命名空间,我也不是很熟这一块,可以参考
XML解析中的namespace初探
Validate XML: 验证 XML 是不是 well formed。
Ignore Whitespace: 忽略空格字符
Fetch External DTDs: 获取外部的 DTD 文件
Return entire XPath fragment instead of text content?: 这个很简单,举个例子:
html 片段是:
<titile>
Apache JMeter
</title>
那么,//title 会返回 “<title>Apache JMeter</title>“ 而不是 “Apache JMeter”.
Reference Name: 就是用来存放 XPATH 提取出来的值。
XPath Query: XPATH 的查询语句。
Default Value: 默认值。